
Well, I seem to have bumbled my way through the obstacles that yesterday intimidated me so badly. Now I must consider what tasks to take up next.
The most obvious are those necessary for storyworld initialization. I have already gotten the aura-count initialization complete, but now I must figure out how pValues of those aura-counts are handled. I need three influences on those pValues. First is the initialization of those pValues at the outset of the game; that could be integrated into the initialization of the pValues themselves.
Second comes the refresh of pValues that happens during Dream Combat; I have not yet decided the characteristics of this. The simplest solution is to give everybody a partial refresh of all values. Next would be a complete rewrite of all values. Or I could provide selective knowledge; perhaps while in the Dream World, Actors brush past other each other, thereby learning something more about them. Then there’s whatever an Actor learns about his opponent during Dream Combat. Does he learn everything about the opponent? Just the aura count of the aura deployed against him?
Third comes the improvement in knowledge provided by conversations with others. This must be integrated with the existing knowledge, based on the declared uncertainty, the existing uncertainty, and the degree of trust that the listener holds for the speaker. That’ll be a complicated calculation, but it’s straightforward enough.
After thinning the forest for a while…
I have decided to proceed with the ‘selective knowledge’ option. At the end of Dream Combat, each pair of Actors is assigned a random “closest approach” distance, which will be reflected in the Dream Combat animation and will provide the basis for improvements in the knowledge of aura-counts. The brush-past will produce knowledge values with small uncertainty values; the uncertainty values will be added in the standard method. For those not familiar with this, I’ll explain how you combine two uncertain values. We’ll call them x1 and x2, with uncertainties u1 and u2 respectively. Sadly, there’s no simple, standard way to combine these values; all the existing formulae from statistics rely on knowing the number of samples behind each mean and standard deviation. Hence I must cook up my own kluge formula. We begin, as all good problem-solvers, by drawing a picture of the problem:
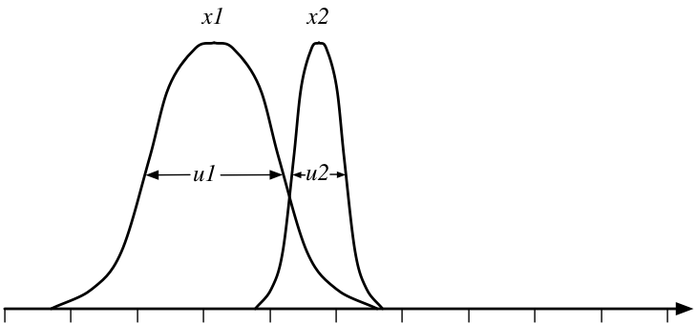
We desire to find the location between x1 and x2 that represents the best compromise between the two values. That best compromise is found where the two curves intersect. Think about it: we assume that these are normal distributions; if so, that means that the height of the curve at any point represents the probability that the true value is the x-value at that point on the curve. Hence, the two curves intersect at the one point where the two probabilities are equal. Here’s the equation for a normal distribution:
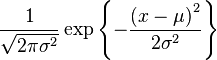
Yuckers! That doesn’t look like fun, does it? Solving that equation for x when we have four values for u1, u2, x1, and x2, is not the kind of thing I want to remember how to do. I could just table-drive the damn thing, but there’s an even simpler way by using a linear approximation: weighting by inverse standard deviations. We start by finding the difference between the two means. I’m too lazy to take you through the derivation; here’s the result:
X = x1 + (abs(x2 - x1) / (u2 + u1)) * u1
Now we need to find U, the uncertainty resulting from this combination. Again, doing this is easy so long as you have N, the number of data points being used, but we don’t have that, so I’m going to kluge up something truly outrageous: the average of the u1 and u2. I know that the final result should have uncertainty less than u1 and more than u2, so I’ll just pick the middle. Again, I won’t bother explaining how I know that the net uncertainty must fall between the upper and the lower; it’s another one of those geometric concepts.
U = (u1 + u2) / 2
OK, time to get coding!