
If you could look into the heart of a computer, you would find no spreadsheets, no programs, no words to process, no aliens to blast. All you would find are binary digits: 1s and 0s. That’s all there is. So how do we get numbers, words, photographs, and aliens out of 1s and 0s?
This is not a new problem: human beings have been dealing with this problem for more than a hundred thousand years: we assign meanings to sounds. That’s the entire trick: assigning meaning to something else. You’re doing it right now by reading these words. They’re just little squiggles, but you translate those squiggles into ideas. If you can translate little sounds into meanings, and little squiggles into meanings, why shouldn’t a computer be able to translate 1s and 0s into meaning?
Dictionaries
Translating sounds and squiggles into meanings is not automatic. There’s nothing in the world that automatically requires what these squiggles mean:
Walk
It’s completely arbitary. That’s why we have to memorize what all these things mean. That’s why we have dictionaries that list what all those words mean.
But it’s not totallly arbitrary; there are also some rules — procedures! — that go along with the dictionaries. For example, you don’t need to go to the dictionary to know what this word means:
Walked
Once you know what “walk” means, you automatically know from the rules what “walked” means. The same thing goes for “walking” and “walker”. The point I’m making is that understanding what one set of symbols means requires BOTH some data (the dictionary) and some processing (the rules).
Once you understand this principle, you’re all set to understand how computers get from 1s and 0s to all sorts of other things. Here goes:
Binary numbers
The easiest translation is from groups of 1s and 0s to full numbers. You just use regular binary numbers. For example,
100110 = 38
Word Size
Computers don’t grab bits one at a time; instead, they grab them one word at a time. A word is, from the point of view of the computer, one handful of data. The computer grabs data one word at a time. Here’s the trick: old-time, primitice computers like the ones I started with had a word that was only eight bits long. In other words, the biggest possible number those computers could handle internally was:
11111111 = 255
Pretty pathetic, huh? Nowadays, computers have a word size that is 64 bits long, so the biggest number they can handle is
1111111111111111111111111111111111111111111111111111111111111111
which equals 18,446,744,073,709,551,615. That’s better, isn’t it?
But we do a lot more with binary numbers than just convert them to decimal numbers. We can use binary numbers to represent all sorts of things, such as:
Letters in the alphabet
It’s easy to translate numbers into letters; all you do is set up a conversion table. Way back in 1960, computer people set up a system called the American Standard Code for Information Interchange, abbreviated to ASCII. It’s a seven-bit code table that translates numbers to letters. Here’s a table of ASCII codes:
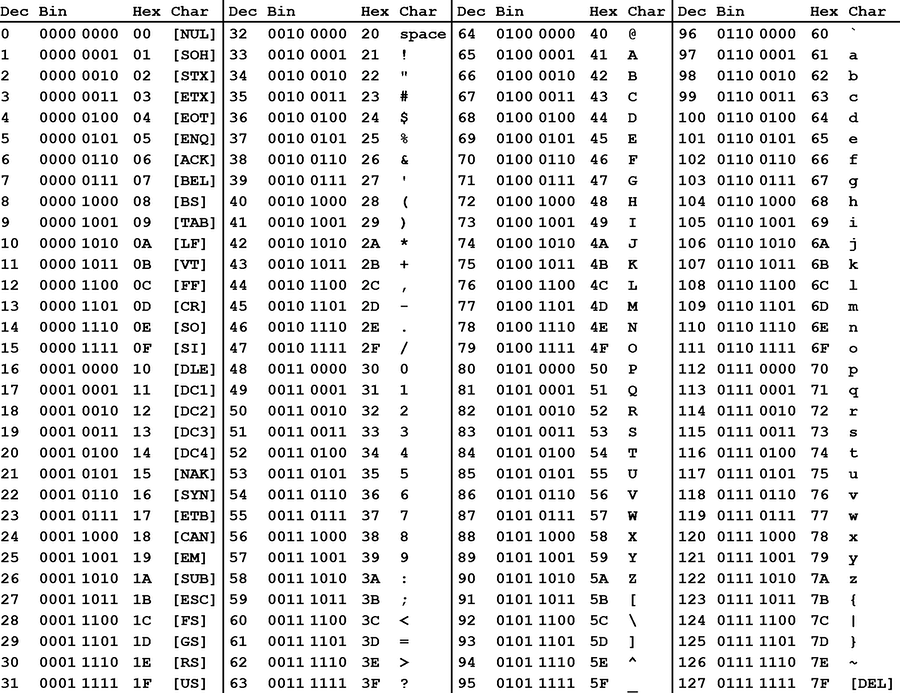
The first 32 characters are all special characters used to tell computer terminals to do things like ring a bell, end a line of text, and so forth. The regular alphabet doesn’t start until decimal number 65. This table has most of what you want: letters, numerals, typographical and mathematical symbols — it really does cover almost everything you’d want for regular communications. So all you have to do to use ASCII is to store this table inside your computer, and whenever you want to translate a number to a letter, just use the table. Easy peasy, right?
Ah, be we can get much more complicated than that. In the 1980s, people realized that foreigners needed to use computers, too, and the ASCII codes didn’t have all the letters that foreigners need. So they set up a brand new, spiffy system called Unicode. There are different flavors of Unicode, and nowadays they even include the codes for zillions of emojis. Isn’t that nice? 😀
Sounds
Let’s not forget all those wonderful sounds that come out of your computer. From the various bleeps and bloops alerting you to significant events, to the extended alerts (“You’ve got mail!”), to full-blown music, computers make sounds according to a very simple system. Sound is nothing more than waves of air pressure. Here are the sound waves in the word “the”:

To record the sound, you need only record the number for the amplitude of the wave at each point in time. Here’s a blowup of a tiny portion of the above sound, with the time shown at the top:
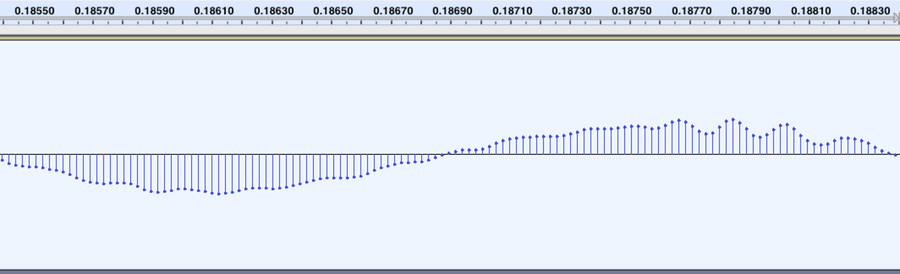
As you can see, we need only record a table of all those amplitudes to record the sound. Unfortunately, this table will be rather large. You see, this data records 40,000 numbers every second. With 16-bit resolution and two channels, that adds up to 160 KB of data per second. To record one of Beethoven’s symphonies — 70 minutes long — would require 672 MB of data. Now, back in the good old days maybe ten years ago, that would eat up a lot of space. So computer people came up with a way of compressing the data down to something much smaller. My recording of Beethoven’s Ninth Symphony eats up less than 100 MB of storage space. This is accomplished with a bunch of mathematical tricks. There are lots of different mathematical tricks you could use to compress music. Each trick has its own combination of strengths and weaknesses. No single set of tricks is obviously superior to any other single set of tricks.
This means that you can use any of the different tricks. Each one is called a format. Wikipedia has a list of 40 different formats for audio recordings. This is really great if you’re a professional who wants the ideal format for a particular problem. If you’re a normal schmuck like me, this kind of thing drives you crazy.
Colors
We can use numbers for colors, too. The trick here is that scientists have found that we can make any color at all simply by mixing different amounts of three fundamental colors: red, green, and blue. It’s like mixing paint. Here are some examples of color combinations:
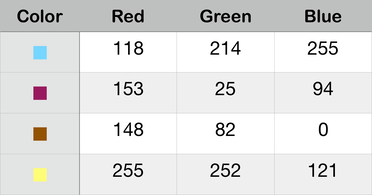
Harken back to the paragraph above describing word sizes. Remember how we can have 8-bit words or 16-bit words or 64-bit words? The numbers used to specify colors are always 8-bit numbers, ranging from 0 to 255. Here’s the same table, only it uses percentages to show how much of each color is used in the mixture:
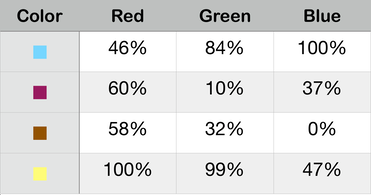
So it takes just three numbers to specify a color. Each of those numbers is an 8-bit word. So we need a 24-bit word to store a color. For rather messy reasons, we actually use a 32-bit word; I won’t bother you with the explanation.
Images
Audio data is really just a long one-dimensional table of numbers. Now let’s talk about images. They are TWO-dimensional: they have height and width. We break an image up into little pieces, and store a number for the color in each little piece. We call those little pieces pixels. Here’s a blow-up of the letter “a” on this page:
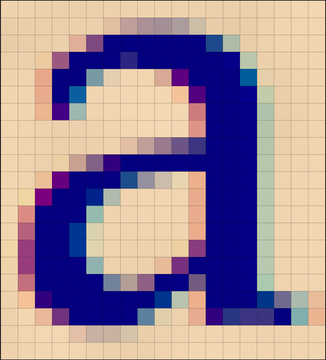
Each of the pixels is designated by a square. There are 21 horizontal rows, each 19 pixels wide. We top row of pixels are all the same, so we store that row as a set of 21 pixels, each of color [red: 234 green: 211 blue: 178]. We computer pros just shorten it to (234, 211, 178).
The second row of pixels is mostly the same color, but the seventh pixel is slightly different; its color is (220, 191, 165). The pixel after that is (186, 159, 154). And so we walk through each pixel from left to right, recording the exact color mixture in each pixel. We end up with a huge two-dimensional table of color mixtures. That’s how we record an image.
As you can imagine, this will cost a lot of memory. The little “a” is 19 pixels wide by 21 pixels high; therefore, it has 399 pixels in total. Each pixel uses up a 32-bit word (four bytes). That means we need 1,596 bytes just for the image of that little “a”. Now look at all the letters on this page and imagine how many bytes are needed for that. Cowabunga!
But the same computer people who figured out mathematical tricks to compress music have also figured out other mathematical tricks to compress images. Just like audio formats, we have gobs of different formats for storing images. Here’s the Wikipedia page describing the zillion different formats for images. For most people, there are only three file formats that are important: JPEG, PNG, and GIF. I don’t like GIF, so I won’t tell you about it. The difference between PNG and JPEG is that PNG is lossless, while JPEG is lossy. This means that the PNG version will always be a perfect rendition of the image, while a JPEG version will be a little fuzzy. The only reason we use JPEG is to save space on images. Depending on a great many factors, a JPEG image can require only one-tenth as much space as the equivalent PNG image. That’s why almost all the images you see on the Internet are stored in JPEG format. With fewer bytes to download, the pages load faster.
Video
Lastly we come to video. Sounds are one-dimensional (time), while images are two-dimensional (height and width). Video is three-dimensional: the height and width of the image plus time. That makes movies very large. When the classic video All Your Base Are Belong To Us came out in 2001, it took me two hours to download it over my telephone line’s modem. It was really important to compress these videos way down! Even nowadays it is important to compress videos so that they don’t eat up too much bandwidth. As you might expect, there are lots of video formats, although nowadays most people seem to have settled on just a few: MPEG and M4V. These formats do an impressive job of compressing video way, way down. Let’s consider, for example, a typical movie that is 100 minutes long. At 30 frames per second and 60 seconds per minute, that adds up to 180,000 frames of image. Each frame of an HDTV movie contains 2 million pixels; at four bytes per pixel, that means that our movie requires about 1.5 TB of data. That’s a lot of bytes! However, video compression algorithms cut that down to about 5 GB — only about 0.3% of the original! That’s impressive compression!
Code
One last form that data can take: program code. A program consists of a sequence of numbers that tell the central processing unit what to do. Each number means something different. The numbers used by modern computers are really complicated, but here’s an example from the good old days when computers were smaller and simpler:
173 8517
105 35
133 8517
The first number (173) means “get a number out of memory” and the second number (8517) tells the CPU the memory location to retrieve the number from: memory address number 8517. The third number (105) tells the CPU to add the fourth number (35) to the number it just retrieved from memory. The fifth number (133) tells the CPU to store the result back into memory location number 8517. In other words, this little bit of code gets the number stored in memory location 8517 and adds 35 to it, then stores the result back into memory location number 8517.
Conclusion
The point of all this is that we can use numbers to mean all sorts of different things. Depending on how we choose to interpret it, a number can represent an integer like 13 or 153, a floating point number like 3.1415936523, a sound, an picture, a video, or a computer program. It’s just a matter of interpretation. And therein lies the important lesson for you. Numbers are powerful, but a number is not information. A number becomes information only when we interpret it according to some agreed-upon rule — and people can always play games with the rules in ways to produce misleading conclusions. The rule by which you interpret a number is just as important as the number itself.
