
Anti-Randomness!
I have a bit of a shock here. It’s almost certainly due to a mistake of my own, but in order to ferret out that mistake, I want to write everything down so I’m certain of what I’m doing – that will make it easier to figure out what I’m doing wrong. Here’s the situation:
If Leonids came nonrandomly, then you’d expect them to fall in tight clusters. How tight is “tight”? In my work reported on March 27th, I demonstrated that there is an unquestionable nonrandomness for Leonids that are close together in the sky -- only a few degrees apart. However, what if we looked at the entire sky? There were four cameras on board the ARIA aircraft, pointed at all directions around the horizon. Together, they took in a broad swath of the sky roughly a thousand miles in diameter. If nonrandomness extends over large distances, we’d expect a cluster to show up in all four directions at the same time. In other words, during any given chunk of time, we’d expect there to be a correlation between the number of Leonids seen by each of the four cameras. When there’s a cluster of Leonids, it should show up in all four cameras; when there’s a dearth of Leonids, it too should show up in all four cameras.
A proper statistical test of this is horrendously difficult to carry out, because the four cameras are not identical, and they were pointed at different distances from the radiant, which should affect the number of Leonids they’d see. But there is one simple way of detecting correlation. If we simply multiply together the Leonid counts for each of the four cameras in the same period of time, then we’ll get a bigger number if they’re clustered together, and a smaller number of they’re randomly distributed. Here’s a simple numeric example of my meaning. First, let’s imagine two one-minute intervals, in each of which we got the following counts for our four cameras:
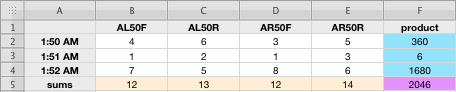
This arrangement shows the Leonids strongly clustered, with a lot of Leonids at 1:50 AM, very few at 1:51 AM, and then a lot at 1:52 AM. But now let’s suppose that they aren’t so strongly clustered, but still have the same number of Leonids. Then the table might look like this:
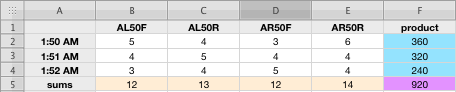
As you can readily see, the clustered, nonrandom table above produces a higher sum of products than the more regular lower distribution. That number in the lower right corner (purple), then, is a rough indicator of how non-random the Leonids are. So I carried out this test using 30-second bins -- that is, the period of time for each count was 30 seconds long; I ran the test for the period from 1:40 AM to 2:56 AM, because there are gaps in the data before and after these times. This still left me with a lot of data. Lastly, I added up the square roots of my numbers (because I was having problems with numeric overflow), and I took the average value per bin. The end result was a value of 17.75.
Great – what does “17.75” mean? How do I know whether that number is big or small? As it happens, there’s a fairly easy way to handle this nowadays: run a bunch of simulations using random data, then compare the random data with the actual data. I ran a quick test with just five random runs and I an average value for the five random runs of 24.1. The random result is higher than the actual result -- this is impossible! So I decided to try the process with different bin sizes: everything between 1-second long bins to 59-second long bins. Here’s the graph of the results:
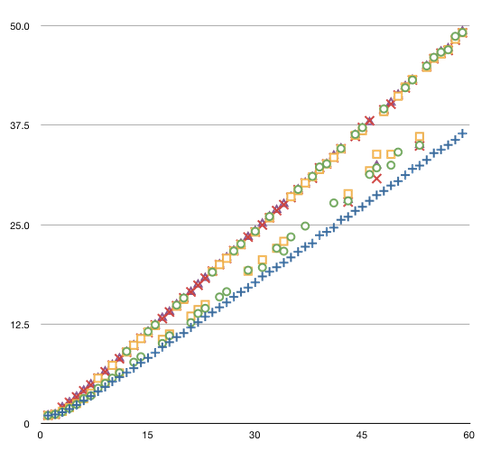
This is quite a shocker. The actual data is the set of blue crosses; the random data is everything else. The actual data is less random than the random data! In other words, it’s more regular. Even worse, the supposedly random data does not exhibit reasonable behavior: it neatly follows two different lines. As Albert Einstein once remarked, “Whut the hay-ull?!?!?” Clearly I have made some atrocious mistake in my programming. Yet, after studying the code for hours, trying some variations, I cannot find anything wrong with it. I’m posting this diary page not as my conclusion, but as a demonstration of how tricky this type of analysis can be. When you’re crunching numbers hard, a tiny oversight can completely screw up everything. I fear that other tiny oversights may have crept into other parts of my analysis. It’s impossible to be certain; there are only two defenses against such mistakes: ferocious critical self-scrutiny, and the humiliation of having other people find mistakes that I should found. It’s all part of the search for truth.