
Step One: Defining the data-gathering process
The first step in this process will be the creation of a list of characters for whom we wish to obtain similarity data. This raises a number of issues. First, in order to get a broad sample of character attributes, we’ll need a broad collection of characters. Yet the number of entries in the resulting matrix increases as the square of the number of characters. If we list only ten characters, there will be a 45 matrix slots requiring data entry. (The formula is squares to fill = (n**2 - n)/2.) (The diagonal of the matrix is automatically filled with zeros.)
Moreover, no respondent will be familiar with all the characters in our list. Fortunately, the interactive capabilities of the Internet give us an easy workaround: we can compile a huge list of characters from all of cinema and then allow the respondent to select the characters to use. I suggest that we start off with a two-character matrix and grow it as the respondent chooses. Thus, the first page might look like this:
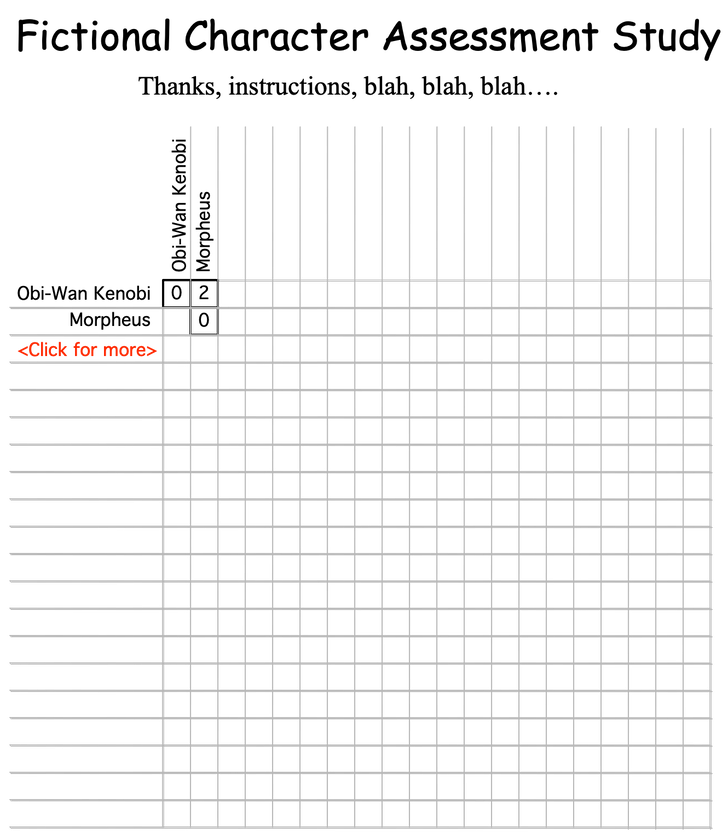
When the respondent clicks on the <Click for more> button, a new page appears showing the current list of selected characters and a list of the movies whose characters are available. Currently that list comprises The Game of Thrones, The Matrix, The Lord of the Rings, Harry Potter, and Star Wars. We can consider other movies, but these movies extend over a long period and so the characters are more fully developed.
Here the respondent has chosen Obi-Wan Kenobi and Morpheus, and rated their similarity as a “2”—they’re very similar. With this done, the respondent can then chose to add another character.
The respondent can continue this process until the matrix is completely filled with twenty character comparisons—a total of 190 data entries, or stop at whatever point they desire.
This is NOT the final list of characters; I just slapped something together. We’ll need to hammer out a good list that meets two criteria: first, the characters on the list must have a high probability of being familiar to most respondents. Second, the characters themselves must span a wide range of attributes. These two criteria are somewhat contrary to each other, because most respondents will be young people whose only experience in fiction will be comic book movies. How many respondents can we expect to know characters like Don Quixote, Huckleberry Finn, Elizabeth Bennett, or Gunga Din?
We’ll need somebody to write up the web page to do this. This will require a bit of server-side coding, although there is a simple way to do it in JavaScript: output the results in text that the respondent copies and pastes into an email. Clumsy.
Step Two: gathering the data
The next step is to recruit lots of respondents. We’ll need several hundred. They enter the data and I collect it.
Step Three: calculate net similarities
For each pair of characters in our master list, we calculate the mean and standard deviation of the respondents’ data.
Step Four: Multi-dimensional analysis
This is rather tricky code, but I’ve done it before, so it shouldn’t be a problem. I’m not sure how the use of standard deviations will affect the code; I may wish to simply throw out pairings with too large a standard deviation.
Step Five: Examination of the tension graph
The result of Step Four will be a tension graph looking something like this:
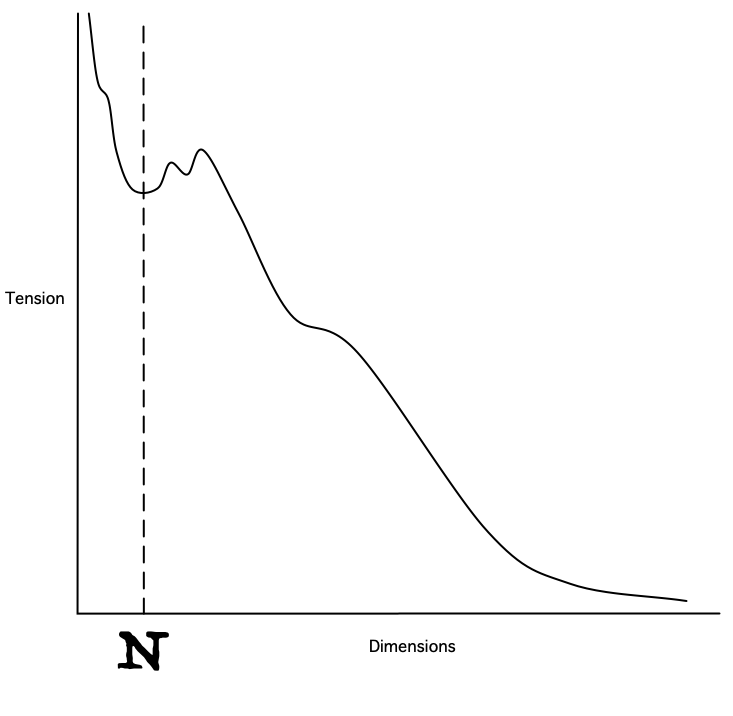
That local minimum marked as “N” represents the optimal number of dimensions to use. We may need to argue about what the best value of N is.
Step Six: Cluster analysis
Once we’ve selected a value for N, I then produce tables of final N-coordinates of each of the characters. With some sorting work, we might be able to identify clusters of characters. This could be very messy if the value of N is high.
Step Seven: characterizing each of the N dimensions
This is the most difficult step; it requires considerable judgement. If we can identify clusters of characters and characterize the characters (e.g., “Villains”, “Heroes”, “sidekicks”, “romantic interests”, etc) and then find dimensions in which one of those clusters has an especially low or high value, we can associate the characteristics of that cluster with that dimension. We can then use this as a fundamental personality attribute.
Step Eight: Repeating the process for a small number of dimensions.
We could also carry out the calculations for two or three dimensions; this would give us two or three personality traits. We might decide that keeping the attribute count is low enough that we need to enforce a low attribute count.
That’s all there is to it! 😛
Appendix: List of Characters to Test
Here is my current list of characters. I have decided to limit it to cinema, largely because I doubt that many of our respondents read books. 🙃
I think it best to present the characters grouped by the movies in which they appear, and with their photos, the better for respondents to recognize them. This will, however, require a big, clumsy user interface.
Game of Thrones

Lord of the Rings

The Matrix

Harry Potter

Star Wars

Star Trek

